하나의 전처리 코드로 여러 개의 파일에 적용시켜야 할 때 사용했던 방법에 대해 포스팅 하고자 한다.
한 디렉토리 내의 여러 파일을 가져와서 반복 작업을 할 때는 os 모듈의 listdir을 사용하면 된다.
os.listdir('파일 경로') 는 파일 경로 내의 파일명을 리스트로 불러와주는 메소드이다.
import os
# path는 파일 경로(str type), lst 변수에 저장
lst = os.listdir(path)
# 디렉토리 내의 파일을 for 문으로 반복
for i in lst:
반복할 코드나의 경우 반복할 코드 안에 전처리 코드를 넣었다.
+ 이 작업을 왜 했냐면...
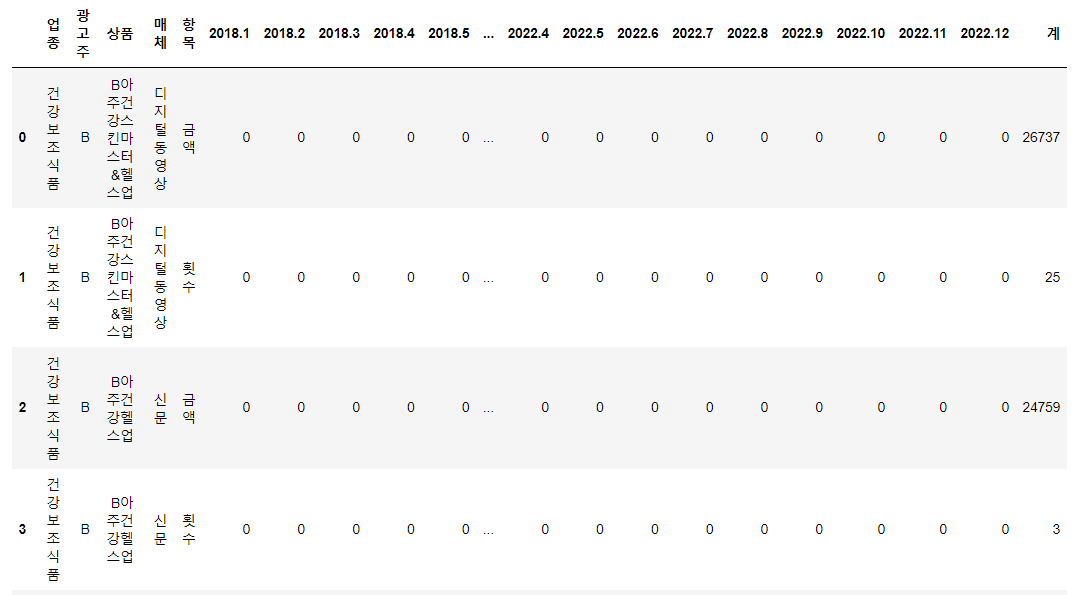
20년도 1월부터 22년 10월까지의 데이터를 받았는데 데이터가 월별로 들어가있고(총 34개 파일) 그 양이 무려 1기가에 달해 어떻게 전처리를 해야하나 고민했다. 한 번에 불러와서 다 붙인 뒤 전처리를 하면 너무 오래 걸리고 중간 중간 테스트 코드 실행도 쉽지 않을 것 같았다.
그래서 일단 샘플 데이터를 가지고 전처리 코드는 완료했는데, 이걸 어떻게 자동화 할까 고민하다가
1. 디렉토리 내 파일을 불러온다
2. 전처리한다
3. 전처리된 파일을 파일명.csv로 저장한다.
4. 1번 다음 파일을 불러온다
5. 전처리한다
6. 파일명.csv 를 불러온다.
7. 5와 6을 합친다
8. 파일명.csv에 저장한다 (덮어씌우기)
이 프로세스로 진행했다.
이 때 raw data 디렉토리와 preprocessed data 디렉토리를 나누어 raw data 디렉토리에 파일명.csv가 저장되지 않도록 했다. 그리고 for문의 앞 뒤에 time 모듈을 통해 소요 시간을 체크했다. 코드를 가지고 있으면 누구나 실행할 수 있도록 디렉토리는 input으로 받았다.
import pandas as pd
import numpy as np
import re
import os
import warnings
import time
from time import time, sleep
# 경고창 무시하는 코드
warnings.filterwarnings('ignore')
# 미리 필요한 요소를 받아주기
path = str(input('file path: '))
path2 = str(input('파일을 저장할 경로'))
lst = os.listdir(path)
start = time() # 전처리 시간 확인
for i in lst:
전처리 코드
try:
old = pd.read_csv(path2 + '파일명.csv') # path2 : 전처리된 파일이 저장될 디렉토리
new = pd.concat([변수명, old])
print('concat 완료')
new = new.drop_duplicates().reset_index(drop=True) # 중복 제거
new.to_csv(path2 + '파일명.csv', index = False)
# 다운로드
except FileNotFoundError:
print('파일을 찾을 수 없습니다.')
# 저장 전 중복 제거
변수명 = orders.drop_duplicates()
변수명.to_csv(path2 + '파일명.csv', index = False)
print(f'{i} 저장 완료')
end = time()
print('소요시간(분):', round((end - start) / 60))중간에 for문 안에 try - except를 통해 파일을 저장하고 다시 불러와서 전처리 해주고 덮어쓰는 과정을 진행했다.
전처리한 파일을 처음 저장할 때에는 '파일을 찾을 수 없습니다' 문구를 내서 전처리한 객체만 저장해주고, 그 이후부터는 이전에 전처리한 파일을 불러와 다시 같은 이름으로 (파일명.csv) 저장해주었다.
참고로 파일명 앞에 \가 자꾸 에러가 나서 디렉토리 절대 경로를 복사한 뒤 뒤에 \을 꼭 붙여주어야 실행이 제대로 된다.
그리고 불러온 파일이 중복 없이 잘 저장되는지 확인하기 위해 전처리가 끝나고 수행이 완료될 때마다 파일 저장 완료 문구를 띄웠다.
전부 전처리가 끝난 파일은 700여 메가에 달해서 총 수행 시간은 20분 대로 걸렸던 것 같다.
개발의 즐거움은 역시,,, 💖 귀찮은 작업을 코드로 자동화하고 나면 뿌듯하다.
'Python' 카테고리의 다른 글
| [Pandas][Analysis] 데이터 분포 및 형태 알아보기: info, describe, boxplot, displot 등 (3) | 2022.10.23 |
|---|---|
| [Python][Pandas] H&M Commerce Data (1) 전처리: 인덱스(.iloc)를 활용한 데이터 슬라이스 (데이터 쪼개기) (4) | 2022.09.09 |
| [Pandas] index 설정, sequence id 컬럼 생성 (6) | 2022.08.31 |
| [데이터전처리(2)][Pandas] 멀티인덱스 해제(.unstack) 및 DataFrame 행렬 전치 (.T) (3) | 2022.05.13 |
| [데이터전처리(1)][Pandas] DataFrame 그룹핑 (.groupby, .pivot_table) (1) | 2022.05.11 |