분석에 필요한 통계량이 필요할 때, 우리는 평균(mean), 중앙값(median), 분산(variance), 표준 편차(standard deviation) 등을 주로 고려한다. 이 때, 연산하는 숫자들의 단위가 달라지면 크기를 비교하기 어렵기 때문에 우리는 '표준화' 라는 작업을 거치게 된다.
숫자들의 단위가 달라지면 왜 크기를 비교하기 어려운가요? (더보기 클릭)
아주 단순한 데이터셋을 가지고 가격에 따른 만족도를 비교 해보자.
| 가격 | 만족도(1 ~ 5) |
| 3000 | 5 |
| 4500 | 4 |
| 6000 | 3 |
| 7500 | 2 |
| 9000 | 1 |
우리는 본능적으로 만족도 1을 올리기 위해서는 가격이 1500 낮아져야 한다는 음의 상관관계를 파악할 수 있다.

만약 두 변수의 기울기 변화를 같이 보고싶다면 어떻게 해야할까? 한 그래프 안에 두 변수의 기울기를 측정하는 그림을 그리면 아래와 같이 나타난다.

절대 가치로 평가했을 때, 가격의 변화(기울기)에 비해 만족도의 변화(기울기)는 너무도 미미해보이지만, 사실 우리는 알고있다. 저 주황색이 두 칸(1단위) 움직일 때마다 파란색은 1500씩 움직여야 한다는 것을. 그림으로만 보면 가격이 만족도에 주는 영향이 거의 없어보이게 표현되지만, 사실 위 데이터에서 만족도를 예측하기 위해서는 가격이라는 요소가 크게 작용하게 된다.
이렇게 두 변수 간의 크기 차이가 많이 나는 경우에는 통계치를 확인했을 때 평균, 분산, min, max 값의 차이가 많이 나게된다.
이처럼 두 데이터 간의 기울기 크기의 차이가 다를 때 (즉, 단위가 다를 때) 우리는 직관적으로 크기 비교를 하기 어려워진다.
scaler 의 종류
iris dataset을 이용하여 아래의 세 가지 scaler에 대해 알아보자.
0. iris dataset?
iris(붓꽃) 의 꽃받침과 꽃잎의 넓이, 길이를 측정하여 붓꽃 3종 (setosa, versicolor, virginica)을 주로 예측하는 데에 많이 쓰이는 (아주 유명한)데이터 셋이다. 얼마나 유명하냐면, 사이킷런에서 샘플 데이터로 제공할 만큼 유명하다.
from sklearn.datasets import load_iris
iris = load_iris()위와 같은 코드로 불러올 수도 있지만, 결과를 프린트하면 array 형태로 나오기 때문에 가독성이 좋지 않아 파일 데이터를 통해 DataFrame 형태로 가져왔다.
>> load_iris()로 가져오는 법 (더보기 클릭)
1. array의 구조를 살펴보면 dictionary 형태로 되어있는 것을 알 수 있다. data, target, target_names, DESCR(어떤 데이터셋인지 설명), feature_names, file_name, data_module
2. data가 우리가 분석해야되는 데이터 셋이 되고 target은 맞춰야하는 종속 변수 즉, 붓꽃의 종류가 된다.
3. array로 되어있기 때문에 dict를 하나씩 빼서 가독성좋게 DataFrame으로 만들어보면
import pandas as pd
pd.DataFrame(iris.data)
정보를 알아보기 쉽지 않다. columns의 값으로 feature_names (list)를 붙여주고
target도 마찬가지로 df로 만들었을 때 (코드 생략)

컬럼명을 붙여줘야 알아보기 쉬울 것 같다. target_names에 의하면
'target_names': array(['setosa', 'versicolor', 'virginica'], dtype='<U10')0: setosa, 1: versicolor, 2: virginica 이다.
iris train data (data)에 columns 붙여주기
iris_train = pd.DataFrame(iris2.data) #train data로 학습시킬 데이터 가져오기, df로 만들어서 변수 저장
iris_train.columns = iris.feature_names #iris_train의 컬럼 이름은 iris(사이킷런에서 가져온 것)의 feature_names의 값입니다~OUT:

iris 파일이 없다면 이렇게 만들어준 데이터 셋으로 조물조물 할 수 있다.
describe() 함수를 통해 수치형 데이터의 분포를 살펴보았다.
iris.describe()
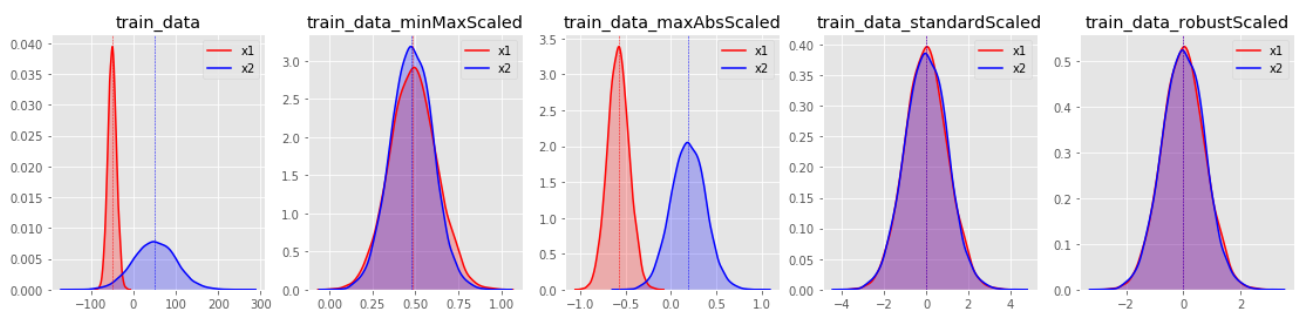
sepal(오늘의 영단어: 꽃받침)과 petal(오늘의 영단어2: 꽃잎)의 전체적인 분포가 표준편차(std)도 크게 나타나고, min-max의 값도 상당히 차이나기 때문에 데이터를 같은 범위 안에 들어가도록 예쁘게 갈아줄 필요가 있을 것 같다.
1. Standard Scaler
기존 변수를 평균이 0이고 표준편차가 1인 표준정규분포로 만드는 스케일러
평균과 표준 표준 편차를 쓰기 때문에 이상치에 민감하다.
scikit-learn preprocessing의 StandardScaler 패키지를 사용한다.
from sklearn.preprocessing import StandardScaler #모듈 불러오기
standardscaler = StandardScaler() #객체에 저장해줍니다.
standardscaler.fit(train_data) #scaling
std_iris = standardScaler.transform(iris)
#train_data를 스케일링 된(학습된) 형태로 변환하여 변수에 저장해줍니다.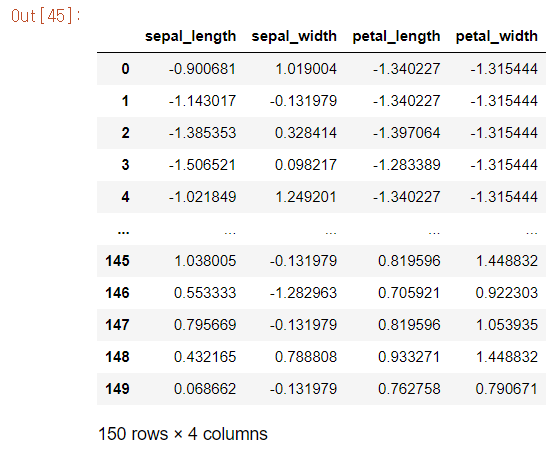
2. Min-Max Scaler
최대값을 1, 최소값을 0으로 설정하는 스케일러
마찬가지로 이상치가 있으면 민감하다.
from sklearn.preprocessing import MinMaxScaler
MinMaxScaler = MinMaxScaler()
MinMaxScaler.fit(train_data)
min_max_iris = MinMaxScaler.transform(train_data)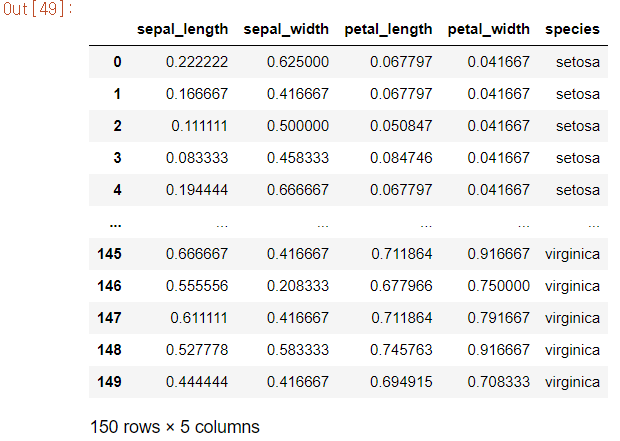
3. Robust Scaler
중앙값(median)과 IQR을 사용하여 outlier 대해 안정적으로 방어할 수 있는 스케일러 (그래서 robust)
from sklearn.preprocessing import RobustScaler
robustScaler = RobustScaler()
print(robustScaler.fit(train_data))
train_data_robustScaled = robustScaler.transform(train_data)
이에 더 자세히 데이터 분표별 스케일링 값을 가져오는 블로그가 있어 소개를 하려고 한다,
https://mkjjo.github.io/python/2019/01/10/scaler.html